")
MinIO na Prática
Instalação, configuração, integração com GAIO, ClickHouse e envio de dados via Python
Para ter acesso as gravações, se registre em: Grupo de Estudos
Rodrigo Granado Bittencourt | Alessandro Binhara
Azuris Company — Março de 2026
1. O que é o MinIO?
MinIO é um sistema de armazenamento de objetos de alto desempenho, código aberto e compatível com a API do Amazon S3. Foi projetado para funcionar tanto em nuvem nativa quanto em infraestrutura local (on-premise), permitindo armazenar grandes volumes de dados não estruturados — como arquivos Parquet, CSVs, backups, logs e imagens — com escalabilidade e velocidade.
Por ser compatível com S3, qualquer ferramenta que se integra ao Amazon S3 também funciona com MinIO sem alteração de código. Isso inclui o ClickHouse, Python (biblioteca minio), Apache Spark, dbt e o próprio GAIO.
| Característica | Detalhe |
|---|---|
| Protocolo | S3-compatible (mesma API do Amazon S3) |
| Porta de console | 9001 (interface web de administração) |
| Porta de API | 9000 (conexão com bancos, GAIO e Python) |
| Formato recomendado | Parquet (colunar, comprimido, tipado) |
| Licença | AGPL-3.0 (código aberto) |
2. Instalação no Linux
A versão utilizada neste documento é a de Abril de 2025. Os comandos abaixo realizam o download do binário, ajustam as permissões e movem para o diretório padrão do sistema:
Download e instalação do binário
# 1. Baixar o binário (versão Abril 2025) wget https://dl.min.io/server/minio/release/linux-amd64/archive/minio.RELEASE.2025-04-22T22-12-26Z # 2. Dar permissão de execução chmod +x minio.RELEASE.2025-04-22T22-12-26Z # 3. Mover para o PATH do sistema com nome padronizado sudo mv minio.RELEASE.2025-04-22T22-12-26Z /usr/local/bin/minio
Configuração do serviço (usuário e senha)
As credenciais de acesso ao MinIO são definidas no arquivo de serviço do systemd. Para editar:
# Abrir o arquivo de configuração do serviço sudo nano /etc/systemd/system/minio.service # Caso não saiba o caminho, use o comando abaixo para localizar: systemctl cat minio # Retorna o caminho completo do arquivo e suas configurações
Dentro do arquivo, as variáveis MINIO_ROOT_USER e MINIO_ROOT_PASSWORD definem o usuário e senha de acesso ao console e à API.
3. Acessando o MinIO
O MinIO expõe duas portas distintas, com propósitos diferentes:
| Porta | URL | Para que serve |
|---|---|---|
| 9001 | http://(seu-servidor):9001 | Console web — administração, buckets, chaves de acesso |
| 9000 | http://(seu-servidor):9000 | API S3 — conexão com GAIO, Python, ClickHouse |
Criando chaves de acesso
Para conectar ferramentas externas ao MinIO (GAIO, Python, ClickHouse), é necessário criar chaves de acesso (Access Key e Secret Key) — diferentes das credenciais de login do console. Para isso:
- Acesse o console em http://(seu-servidor):9001
- No menu lateral, acesse Access Keys
- Clique em Create Access Key
- Copie e guarde a Access Key e a Secret Key geradas
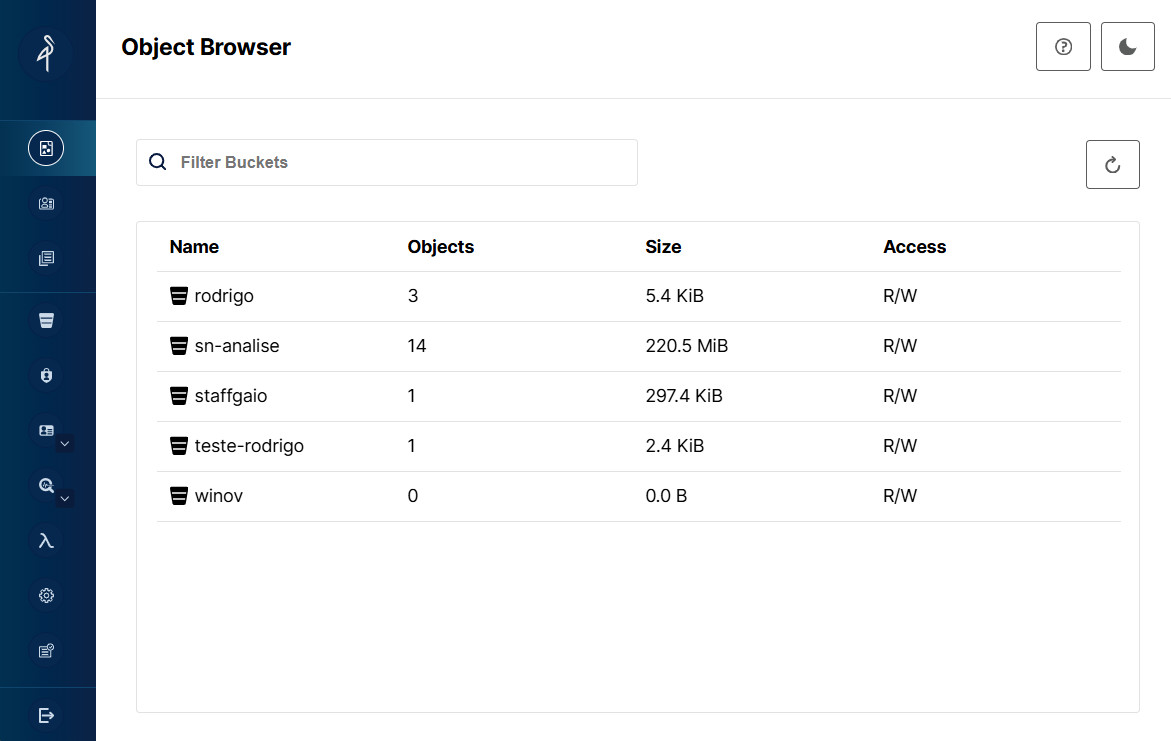
4. Integração com o GAIO
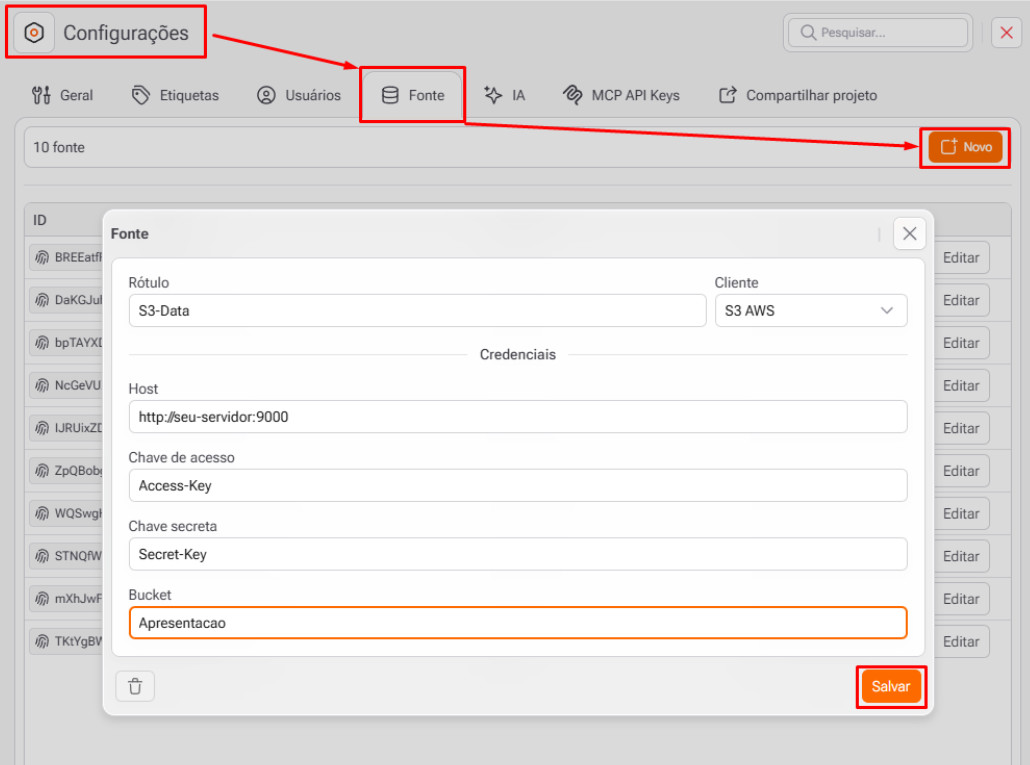
Adicionando o MinIO como fonte de dados
Para conectar o GAIO ao MinIO, acesse as configurações de Data Sources e adicione uma nova fonte do tipo S3/MinIO. Os campos necessários são:
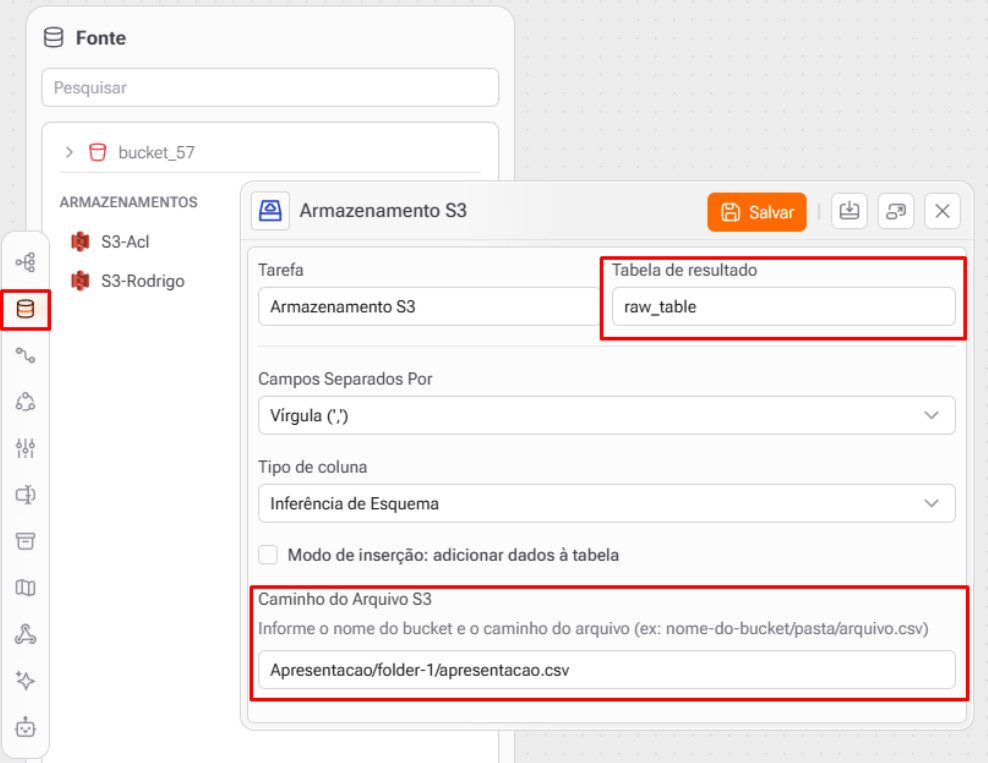
Criando uma tabela de resultado no GAIO
Após adicionar a fonte, é necessário criar uma tabela de resultado dentro de um projeto para que os dados do MinIO fiquem acessíveis para consultas e fluxos:
- No menu lateral do GAIO, acesse Fontes e Armazenamento
- Selecione a fonte do MinIO recém-criada
- Clique em Adicionar tabela de resultado
- Defina o nome da tabela e o bucket/prefixo de destino
O GAIO permite consultar arquivos Parquet diretamente do MinIO usando SQL. A conexão exige as chaves de acesso e o caminho do bucket:
-- Exemplo de SELECT em arquivo Parquet no MinIO via GAIO
SELECT
cnpj,
sum(valor) AS total_pago
FROM s3(
'http://198.161.83.144:9000/meu-bucket/dados/*.parquet',
'minha-access-key',
'minha-secret-key',
'Parquet'
)
GROUP BY cnpj
ORDER BY total_pago DESC
LIMIT 20
Criando tabela permanente a partir do MinIO
Para transformar os dados do Parquet em uma tabela persistente dentro do GAIO (evitando consultar o MinIO a cada acesso):
-- Criar tabela com os dados do arquivo Parquet
CREATE TABLE minha_tabela AS
SELECT *
FROM s3(
'http://198.161.83.144:9000/meu-bucket/dados/part_0001.parquet',
'minha-access-key',
'minha-secret-key',
'Parquet'
)
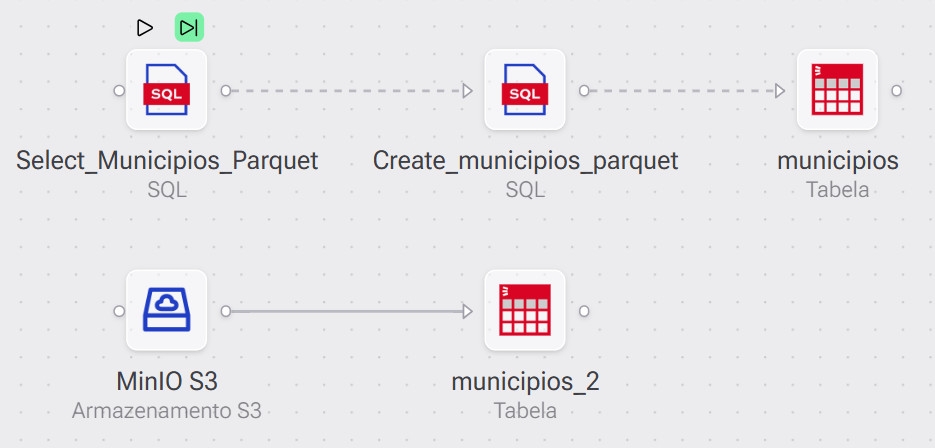
Criando fluxos no GAIO
Além de consultas SQL diretas, o GAIO permite criar fluxos que combinam leitura do MinIO com transformações e carga em tabelas de resultado. Há duas abordagens principais:
- Via SQL: usando SELECT com a função s3() como fonte e INSERT INTO como destino
- Via conector MinIO: criando um fluxo visual que aponta diretamente para um bucket, sem escrever SQL manualmente
Carga de dados do MinIO para o ClickHouse com o Gaio Data OS
O GAIO Data OS permite criar fluxos visuais de carga que leem dados diretamente do MinIO e gravam em tabelas do ClickHouse, sem necessidade de scripts externos
Etapa 1 — Criar a tabela de destino no ClickHouse
Antes de carregar, defina a tabela onde os dados serão armazenados. Isso pode ser feito via SQL no próprio GAIO:
CREATE TABLE IF NOT EXISTS minha_base.apresentacoes ( Nome_Apresentador String, Qnt_pessoas UInt32, Tema String ) ENGINE = MergeTree() ORDER BY Nome_Apresentador
Etapa 2 — Criar o fluxo de carga
Há duas formas de montar o fluxo:
Via SQL direto:
INSERT INTO minha_base.apresentacoes SELECT Nome_Apresentador, Qnt_pessoas, Tema FROM s3( 'http://198.161.83.144:9000/staffgaio/apresentacao.csv', 'minha-access-key', 'minha-secret-key', 'CSVWithNames' )
Via conector visual:
No GAIO, crie um novo fluxo, selecione a fonte MinIO como origem e a tabela do ClickHouse como destino. O mapeamento de colunas pode ser feito arrastando os campos da origem para o destino. Ao executar o fluxo, os dados são transferidos automaticamente.
Quando usar cada abordagem:
| Situação | Abordagem recomendada |
|---|---|
| Carga única ou teste rápido | SQL direto com INSERT INTO ... SELECT FROM s3() |
| Carga recorrente e agendada | Fluxo visual no GAIO com agendamento |
| Vários arquivos Parquet no mesmo bucket | SQL com wildcard *.parquet |
| Equipe sem experiência em SQL | Conector visual do GAIO |
Para arquivos grandes em formato Parquet, o wildcard permite carregar todos os arquivos de uma vez:
INSERT INTO minha_base.dados_consolidados
SELECT *
FROM s3(
'http://198.161.83.144:9000/meu-bucket/colecao/*.parquet',
'minha-access-key',
'minha-secret-key',
'Parquet'
)
Essa abordagem é ideal para pipelines que enviam dados em lotes (como o exemplo do MongoDB na seção anterior), onde cada lote gera um arquivo part_0001.parquet, part_0002.parquet etc. O ClickHouse lê todos de uma vez e consolida em uma única tabela.
5. Enviando Arquivos para o MinIO via Python
Instalação da dependência
pip install minio
Inserção manual pelo console
Para envios pontuais, o próprio console web do MinIO oferece upload direto:
- Acesse http://(seu-servidor):9001
- Entre no bucket desejado
- Clique em Upload e selecione arquivo ou pasta
Envio de CSV via Python
Exemplo mínimo para enviar um arquivo CSV local para um bucket no MinIO:
from minio import Minio
client = Minio(
'198.161.83.144:9000',
access_key='minha-access-key',
secret_key='minha-secret-key',
secure=False
)
# Envia o arquivo 'apresentacao.csv' para o bucket 'staffgaio'
client.fput_object(
bucket_name='staffgaio',
object_name='apresentacao.csv', # nome no MinIO
file_path='apresentacao.csv', # arquivo local
)
print('Upload concluído!')
Envio de Parquet em memória (sem disco)
Para volumes grandes, a abordagem mais eficiente é converter o DataFrame diretamente para Parquet em memória e enviar ao MinIO sem gravar nada em disco. O BytesIO cria um buffer temporário na RAM que é descartado após o upload:
from minio import Minio
from io import BytesIO
import pandas as pd
client = Minio('198.161.83.144:9000',
access_key='minha-access-key',
secret_key='minha-secret-key',
secure=False
)
# DataFrame de exemplo
df = pd.DataFrame({'cnpj': ['123', '456'], 'valor': [100.0, 200.0]})
# Passo 1: serializar DataFrame em Parquet na memória RAM
buffer = BytesIO()
df.to_parquet(buffer, index=False, engine='pyarrow')
buffer.seek(0) # volta o cursor para o início do buffer
# Passo 2: enviar o buffer direto para o MinIO
client.put_object(
bucket_name='meu-bucket',
object_name='dados/part_0001.parquet',
data=buffer,
length=buffer.getbuffer().nbytes,
content_type='application/octet-stream',
)
# O buffer é automaticamente descartado — zero arquivos em disco
print('Parquet enviado ao MinIO!')
O fluxo completo em memória é:
| Etapa | O que acontece | Usa disco? |
|---|---|---|
| DataFrame | Lista de dicionários convertida em DataFrame pandas | Não |
| BytesIO() | Buffer temporário criado na RAM | Não |
| to_parquet() | DataFrame serializado em formato Parquet dentro do buffer | Não |
| put_object() | Buffer enviado ao MinIO via API HTTP | Não |
| del buffer | Buffer descartado — memória liberada | Não |
Envio em lotes de grande volume (MongoDB → MinIO)
Para volumes bilionários, a pipeline lê o MongoDB em lotes de 50.000 documentos, acumula até 500.000 registros e envia cada lote como um arquivo Parquet separado:
TAMANHO_LOTE = 500_000
lote, parte = [], 0
cursor = collection.find({}, batch_size=50000, no_cursor_timeout=True)
for doc in cursor:
lote.append(transformar(doc)) # dict com campos tipados
if len(lote) >= TAMANHO_LOTE:
parte += 1
df = pd.DataFrame(lote)
buffer = BytesIO()
df.to_parquet(buffer, index=False, engine='pyarrow')
buffer.seek(0)
client.put_object('meu-bucket',
f'colecao/part_{parte:04d}.parquet',
data=buffer,
length=buffer.getbuffer().nbytes)
del df, lote # libera memória antes do próximo lote
lote = []
colecao/part_0001.parquet, part_0002.parquet etc., prontos para leitura pelo GAIO ou ClickHouse com wildcard *.parquet.Conclusão
O MinIO se mostrou uma solução eficiente e acessível para armazenamento de dados em larga escala. Sua compatibilidade nativa com a API S3 elimina a necessidade de adaptações ao integrar com ferramentas como GAIO, ClickHouse e Python. A combinação com o formato Parquet — colunar, comprimido e tipado — torna a pipeline mais performática e escalável, reduzindo custos de armazenamento e tempo de consulta.
O envio de dados em memória via BytesIO garante que nenhum arquivo temporário seja criado em disco, o que é essencial para processamento de volumes bilionários em servidores com espaço limitado.
| O que foi coberto | Como fazer |
|---|---|
| Instalação do MinIO | Download do binário + chmod + mv para /usr/local/bin |
| Configurar usuário e senha | sudo nano /etc/systemd/system/minio.service |
| Acessar o console | http://(servidor):9001 |
| Conectar ao GAIO | Data Source S3 com porta 9000 + Access/Secret Key |
| Consultar Parquet via SQL | SELECT * FROM s3('.../*.parquet', key, secret, 'Parquet') |
| Enviar CSV via Python | client.fput_object(bucket, nome, caminho_local) |
| Enviar Parquet sem disco | BytesIO() + to_parquet() + put_object() |
| Envio em lotes grandes | Cursor MongoDB + acumular 500K + enviar por part |