
Pipeline PDF → CSV com IA
Como automatizamos a leitura e organização de currículos em PDF usando Python e Inteligência Artificial
Repositório GitHub: Repositório Github
Para ter acesso as gravações, se registre em: Grupo de Estudos
Rodrigo Granado Bittencourt | Alessandro Binhara
Março de 2026
Apresentação Filtro de Dados de Rodrigo
Introdução
Imagine receber dezenas de currículos em PDF e precisar organizar todas as informações — nome, e-mail, empresa, cargo — numa planilha. Fazer isso manualmente é demorado, cansativo e fácil de errar.
Foi exatamente esse problema que motivou a criação deste sistema. A Pipeline PDF → CSV é uma ferramenta que faz todo esse trabalho de forma automática: ela lê os PDFs, extrai as informações importantes e entrega tudo organizado num arquivo que pode ser aberto no Excel ou importado direto para análise.
Neste artigo você vai entender o que o sistema faz, como instalar, como usar e o que fazer se algo der errado — tudo explicado de forma simples, sem precisar ser programador para acompanhar.
1. O que o sistema faz?
Em resumo: o sistema pega arquivos de currículo em PDF, lê o conteúdo de cada um e organiza as informações numa planilha (arquivo CSV).
Pense assim: é como contratar alguém para abrir cada currículo, copiar os dados importantes e preenchê-los numa tabela — só que de forma automática, em segundos, e sem erros de digitação.
O que entra e o que sai
O sistema recebe PDFs de currículos (especialmente os exportados do LinkedIn) e devolve um arquivo CSV com uma linha por pessoa, contendo os seguintes campos:
| Campo | O que significa |
|---|---|
| Nome | Nome completo da pessoa |
| Endereço de e-mail de contato | |
| Telefone | Número de telefone (somente dígitos) |
| Link do perfil no LinkedIn | |
| Empresa | Empresa onde trabalha atualmente |
| Cargo | Cargo ou função atual |
| Headline | Frase de perfil do LinkedIn (resumo profissional) |
| Nível | Classificação hierárquica de 1 (estagiário) a 5 (CEO) |
Como o sistema classifica o nível de cada pessoa?
O sistema classifica automaticamente cada profissional numa escala de 1 a 5, com base no cargo identificado no currículo:
- Nível 1 — Entrada: Estagiário, Trainee, Assistente, Jovem Aprendiz
- Nível 2 — Operacional: Analista, Técnico, Desenvolvedor Júnior
- Nível 3 — Especialista: Sênior, Pleno, Consultor, Especialista
- Nível 4 — Liderança: Gerente, Coordenador, Head, Supervisor, Lead
- Nível 5 — Executivo: CEO, CTO, Diretor, VP, Fundador, Sócio
2. Como funciona por dentro?
Você não precisa entender os detalhes técnicos para usar o sistema, mas saber o que acontece nos bastidores ajuda a entender por que ele funciona tão bem. O processo acontece em três etapas:
Etapa 1 — Leitura dos PDFs
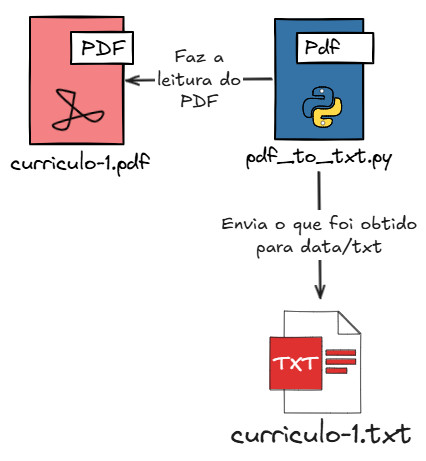
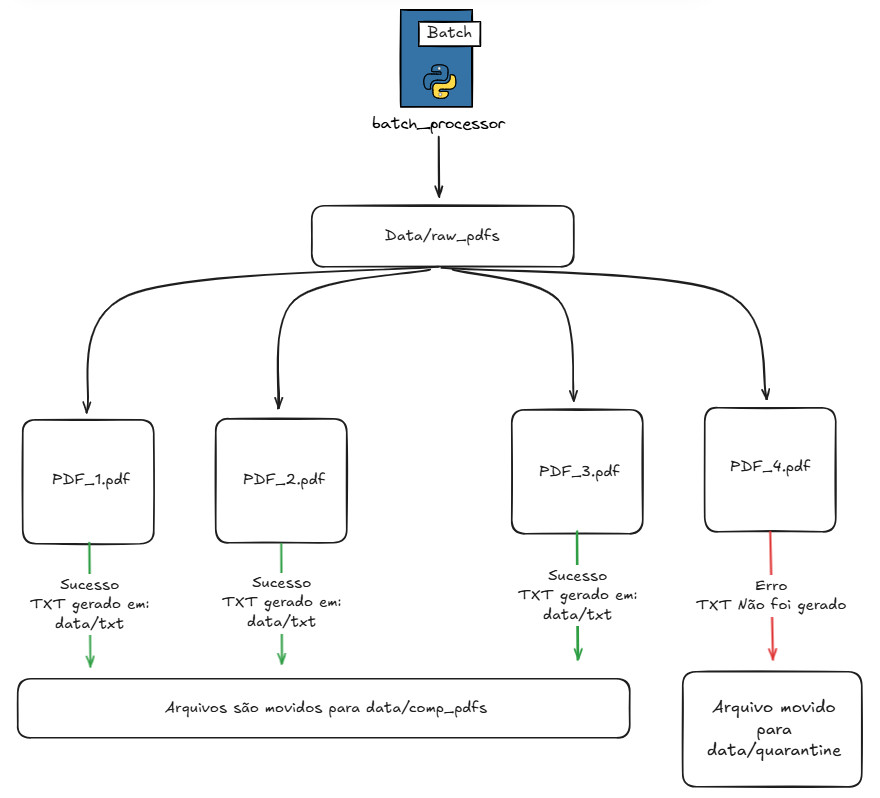
O sistema abre cada arquivo PDF, extrai todo o texto e salva numa versão .txt. É como copiar e colar o conteúdo do PDF num bloco de notas. Arquivos com sucesso vão para a pasta de concluídos; PDFs com problema vão para a quarentena, onde podem ser revisados manualmente.
Etapa 2 — Processamento em lote
Em vez de processar um currículo por vez, o sistema processa todos os PDFs de uma pasta de uma única vez. Basta colocar os arquivos na pasta correta e executar um único comando — o sistema faz o resto automaticamente.
Etapa 3 — Organização com Inteligência Artificial
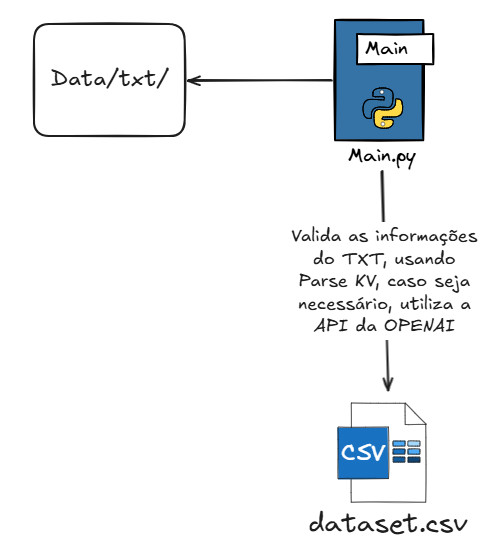
Esta é a parte mais inteligente. O sistema usa duas estratégias para identificar os dados:
- Estratégia rápida (gratuita): se o currículo já tiver os dados organizados de forma clara (como “Nome: João Silva”), a extração é feita diretamente, sem custo adicional.
- Estratégia com IA (via OpenAI): se o currículo for um texto corrido sem formato definido, o sistema aciona a Inteligência Artificial da OpenAI, que lê o texto e identifica as informações automaticamente — assim como um humano faria.
O sistema também usa um cache: se um currículo já foi processado antes, ele não precisa ser processado novamente, economizando tempo e custo de API.
3. Instalação e configuração
Siga os passos abaixo na ordem. Todo o processo leva cerca de 5 minutos.
Passo 1 — Baixe o projeto
Abra o terminal e execute:
git clone https://github.com/AzurisCompany/dplpdftocsv cd dplpdftocsv
Passo 2 — Crie as pastas necessárias
Windows (PowerShell):
$dirs = @('data\comp_pdfs', 'data\logs', 'data\output', 'data\quarantine', 'data\raw_pdfs', 'data\txt')
$dirs | ForEach-Object { New-Item -ItemType Directory -Force -Path $_ | Out-Null }
Write-Host "Pastas criadas com sucesso!"
Linux / Mac:
mkdir -p data/{comp_pdfs,logs,output,quarantine,raw_pdfs,txt}
Passo 3 — Configure sua chave da OpenAI
Para que a IA funcione, você precisa de uma chave de acesso da OpenAI. Pense nela como uma senha que autoriza o uso do serviço.
- Acesse: https://platform.openai.com/api-keys
- Crie uma conta ou faça login e clique em “Create new secret key”
- Crie um arquivo chamado
.envna pasta raiz do projeto - Escreva dentro do arquivo:
OPENAI_API_KEY=cole_sua_chave_aqui
Passo 4 — Instale as dependências
pip install -r requirements.txt
Ou manualmente:
pip install python-dotenv openai pandas pydantic PyPDF2
4. Como usar o sistema
Com tudo instalado, o uso do dia a dia é simples: coloque os PDFs na pasta certa e execute os comandos na ordem.
1. Adicione os PDFs
Copie os currículos para a pasta data/raw_pdfs/:
# Windows copy curriculo_joao.pdf data\raw_pdfs\ # Linux ou Mac cp curriculo_joao.pdf data/raw_pdfs/
2. Processe os PDFs em lote
python src/batch_processor.py
O terminal vai mostrar o progresso em tempo real, indicando quais arquivos foram processados com sucesso e quais tiveram problema.
Se quiser processar um PDF específico em vez de todos de uma vez:
python src/pdf_to_txt.py --input data/raw_pdfs/arquivo.pdf --output data/txt
3. Gere o CSV final
python main.py
Ao terminar, você verá no terminal:
Encontrados: 11 arquivos .txt OK joao-silva.txt | empresa: Nubank | nivel: 4 OK maria-santos.txt | empresa: Itau | nivel: 5 CSV gerado em: data/output/curriculos.csv Registros: 11 OpenAI calls: 8 | KV-only: 3
O arquivo CSV estará em data/output/curriculos.csv, pronto para abrir no Excel ou importar para o GAIO.
5. Visualizando os dados no GAIO
Depois que o CSV é gerado, ele pode ser importado para o ClickHouse e visualizado no GAIO — a ferramenta de análise usada pela equipe da Azuris Company. O GAIO permite criar gráficos e painéis sem precisar escrever código do zero.

Como conectar os dados
- Acesse o GAIO e vá até Data Sources.
- Selecione a conexão com o banco ClickHouse onde os dados foram importados.
- Na seção Tables, localize a tabela de participantes.
Como explorar os dados
- SQL Editor: para fazer perguntas específicas sobre os dados, como “quantas pessoas trabalham em empresas de tecnologia?”.
- Chart Builder: para criar gráficos visualmente, sem código. Escolha a dimensão (ex: Empresa) e a métrica (ex: contagem) e o gráfico é gerado automaticamente.
- Dashboard: para reunir vários gráficos numa tela só, com filtros interativos.
Exemplos de análises
- Gráfico de barras: quantos participantes por empresa
- Gráfico de pizza: distribuição de cargos (analista, gerente, diretor…)
- Tabela filtrada: listar apenas profissionais de nível 4 e 5
- Ranking: as 10 empresas com mais representantes
6. Problemas comuns e como resolver
Erro: “OPENAI_API_KEY inválida” ou “Unauthorized”
- Verifique se o arquivo
.envexiste na pasta raiz do projeto - Abra o arquivo e confirme que a chave começa com sk-
- Certifique-se de que não há espaços antes ou depois da chave
- Se necessário, gere uma nova chave em: https://platform.openai.com/api-keys
Erro: “Nenhum TXT encontrado”
- Verifique se você executou o batch_processor.py antes do main.py
- Confirme que a pasta
data/txt/existe e contém arquivos .txt - Se a pasta não existir, crie-a e reexecute o batch_processor.py
Erro: “ModuleNotFoundError”
Alguma dependência não está instalada. Execute:
pip install -r requirements.txt
PDF processado, mas sem dados no CSV
- Abra o arquivo .txt em
data/txt/e veja se o texto foi extraído corretamente - Se o texto estiver vazio, o PDF pode ser uma imagem escaneada — o sistema não consegue extrair texto de imagens
- PDFs exportados diretamente do LinkedIn funcionam melhor
CSV vazio ou com menos registros do que esperado
- Verifique a pasta
data/quarantine/— PDFs com problema ficam lá - Abra os logs em
data/logs/para ver o que aconteceu com cada arquivo - Confirme que todos os PDFs estavam em
data/raw_pdfs/antes de executar
Como ver os logs de processamento
# Windows type data\logs\nome-do-arquivo_*.log # Linux ou Mac cat data/logs/nome-do-arquivo_*.log
7. Dicas e configurações extras
Economizar créditos da OpenAI
Se quiser usar apenas a classificação local (sem acionar a IA para texto livre), abra o main.py e altere:
USE_OPENAI_FOR_IMPORTANCE = False # usa apenas classificação local
Reprocessar tudo do zero
Se quiser que o sistema ignore o cache e reprocesse todos os arquivos:
# Windows del data\cache\cache.jsonl # Linux ou Mac rm data/cache/cache.jsonl
Verificar status após execução
# PDFs processados com sucesso ls data/comp_pdfs/ # PDFs com problema ls data/quarantine/ # CSV final cat data/output/curriculos.csv
Conclusão
A Pipeline PDF → CSV transforma um processo que levaria horas manuais em algo que acontece em minutos, com padronização e rastreabilidade completa. Cada currículo processado fica registrado, os erros são isolados para revisão e o resultado final está pronto para análise imediata no GAIO.